Over the last several months I’ve been working on creating a federated, offline-capable, data backend for the Weird.one app. This post sums up the latest developments and goes into the rationale behind the experimental Leaf Protocol that has been developed for the use-case.
Further Reading / Context
This builds on previous thoughts and developments touched on in my How to Federate? and Web of Data posts.
I’ll touch on some of the points in those posts briefly here, so they aren’t required reading, but will help to give more context.
Finally, there is a draft Leaf Protocol specification if you want to look into more of the technical details.
The Vision
The vision for Leaf is to empower an Agentic Fediverse. We want to enable things like:
- A social network where you own your data, contacts, and identity
- A local first CMS that can sync to cloud services or your friends over LAN
- Village-scale community networks that can be hosted by the community
- A network of people that can connect to other people
Another Protocol?
Before going further I want to address an inevitable thought: “why are you making another protocol!? We’ve already got ActivityPub, AtProto, Nostr, RDF, IPFS, etc. etc.”
The first reason is that we have priorities for Weird, specifically being local-first and supporting seamless data migration, that are different than most other protocols. Our goal above all else is to make an excellent product, not a protocol. The Leaf Protocol will grow fundamentally out of what Weird needs, not the other way around.
We expose the Leaf Protocol so that multiple Weird instances will be able to federate with each-other. If other apps find Leaf useful, then great, but if not, it’s no problem for us. Furthermore, if the protocol completely fails for whatever reason, we will continue to do what is necessary to make Weird without it. It exists only to serve those benefited by it.
That said, we designed Leaf to be flexible, and useful outside of Weird. We hope that we’ll be able to make bridges between Leaf and other protocols, possibly even using it as an integration layer between different protocols. If we can make Leaf work well for us while still integrating with the wider protocol ecosystem, that would be awesome.
Leaf Concepts
Data vs. Events
One of the big reasons that we started thinking about Leaf was because of the limitations of ActivityPub, or rather, of the ActivityPub servers/standards that we have today.
ActivityPub is fundamentally a way to connect servers to each-other by sharing events.
One of the problems with this is that your server only knows about things that have been sent to one of its inboxes. This can lead to side-effects such as different servers having different reply histories or like counts.
Importantly, your data is bound to your homeserver. Different apps are able to tell each-other about things that happened, and to a certain extent, read data from other servers, but they’re not necessarily able to transfer or migrate a users data, creating a level of lock-in despite the open protocol.
Note: There is more background context on ActivityPub limitations in the Popular Solutions section of the How to Federate post.
For Weird, we wanted to avoid the problems of event synchronization and build instead on data replication. The Leaf protocol is built on stores of data that can be replicated between peers. These peers can be other servers, or even web or desktop clients. The data can be stored and edited offline, and then synchronized to servers later. You can even synchronize to multiple servers if desired, so that if one goes down, your data isn’t lost.
This is a very different experience from most federated apps today, and goes a long way in promoting user agency.
Not a Totally New Protocol
Another important thing about Leaf is that we didn’t just invent a new protocol from scratch. In fact, it’s actually just a thin layer on top of the Willow Protocol.
The Willow Protocol is a work-in-progress protocol specification that satisfies all of our needs for privacy-preserving, local-first, data replication. The only thing we felt was missing was a data format.
Willow only lets you read and write one kind of data: bytes.
Being able to store bytes lets you store any kind of data, but just having a bunch of bytes doesn’t tell you anything about what the bytes mean. That is what Leaf solves for.
An Interoperable Data Format
When thinking about a data format, one of the big questions was how to make it inter-operable. For example, we didn’t want to restrict what kind of data you could store, but we also wanted it to be possible for different servers or apps to read and write each-other’s data so that you weren’t locked in.
To this end we came up with an Entity-Component data model. Entities are almost like webpages. They have a location, like a URL, and entities can link to other entities. Instead of storing HTML, though, entities store a list of components.
Components are little pieces of data that mean something by themselves. For example, most entities
will have a Name and a Description component, and possibly and Image component.
Each different kind of component has a human-readable specification that documents what the component means and how it should be used in apps. It also has a machine-readable data format that describes exactly how the different bytes of the component data map to numbers, lists, text, etc. The specification and the data format are then hashed to create a globally unique component ID.
By breaking entity data up into individual components, different apps are able to incrementally understand entities.
For example, you might have one entity for your public profile, and another entity for a blog post.
Your profile and your blog post would both have Name, Description, and Image components. They
also might have components the other doesn’t, like Friends and Article.
Because each component means something by itself, an app can read whatever components it understands, and simply ignore the ones that it doesn’t. This can be really useful for interoperability.
If I share a link to my profile or my blog post in a chat app, the app can read the Name, Description, and
Image components to generate a link preview, without having to know anything else about the
entity. It doesn’t care if it’s a blog post or a profile, or a picture in my photo album. They all
have components that it understands well enough to show a link preview.
Note: You can get more background on this concept in my A Web of Data post.
Identity
Another question about the protocol design is how to handle identity. Identity is a big topic and in Weird and Leaf we are focusing on leaving options as open as possible.
Strictly speaking an “identity” in Leaf is a cryptographic keypair. The reason for this is that we want users to be able to create and manage their own identity, if desired, without the need for servers or DNS or anything else.
That said, we don’t want to force users to do this. We want you to be able to sign up with your Email address, just like you do with any other app, and start using Weird right away. Cryptographic keys allow us to do this, too, by simply storing the keypair on the server.
Since we’re using keypairs, though, we have to think about what happens if somebody loses a keypair, or if it gets stolen.
My current impression is that users should manage identities as a “contact book”, and that apps should allow users to assign different keys to their own “contacts” as they see fit.
Note: This is not an original concept, and may be done similarly to the Pet Names proposal.
For example, if my friend Alice loses her private key, and then creates a new one on a new server, she can come and tell me in person, or even on another platform, about her new key. I can then update “Alice” in my contact book and all Alice’s new posts with her new “identity” will still be treated as having come from my friend “Alice”.
This model is important I believe, because it divorces the human and machine concepts of “identity” and puts emphasis on the human concept.
The fact is that we must have a machine concept of identity for the sake of efficiency. When we use the internet, though, we can’t create any proof of our human concept of identity, in the machine.
While we are always seeking the holy grail of digital identity, that will somehow allow us to perfectly represent our human identities in the machine, we will probably never find it, and all of our existing solutions may break our trust in some form or another. Our goal, then, is to allow the user the freedom to tell the machine what their idea of identity is, for the times when trust in the machine identity is broken.
Note that we still continue to use DNS as a way to discover other identities. For example, I have a
zicklag@weird.one account that can be used to discover my profile. The weird.one server is also
capable of changing the keypair associated to the name zicklag on that server.
But somebody who has added me as a friend or who has followed me, will have my old keypair in
their contact book, and their app can tell them that the identity associated to zicklag@weird.one
has changed. At that point they can choose to trust the new identity, or they can reach out to me
however they wish and ask if that’s a change that I initiated or if somebody else grabbed my
username after I stopped paying for my account or something like that.
Permissions
Permissions to access data in Leaf is handled completely by the Willow Protocol’s Meadowcap capability system. We don’t have to change anything there!
The capability system allows you to grant read/write access to portions of your data store. This can be used by the Weird server to create a capability that allows read/write access for a user’s desktop/mobile/web application offline. It could also be used to allow another server read-only access to your data as a backup.
These capabilities can be either permanent, or they can have expiration times. Permanent capabilities are irrevocable, so expirations can be used for an extra level of security.
Development Progress
Leaf RPC Server
Just recently we finished the first working prototype of Leaf, and started using it as Weird’s data store. Weird is written in TypeScript with SvelteKit, and our Leaf implementation is written in Rust.
To bridge the language gap, we made a simple Leaf RPC Server that can be connected to over WebSockets. Our TypeScript server can then connect to the Leaf RPC server, similar to how other apps would connect to a PostgreSQL database.
Our latest service architecture now looks like this:
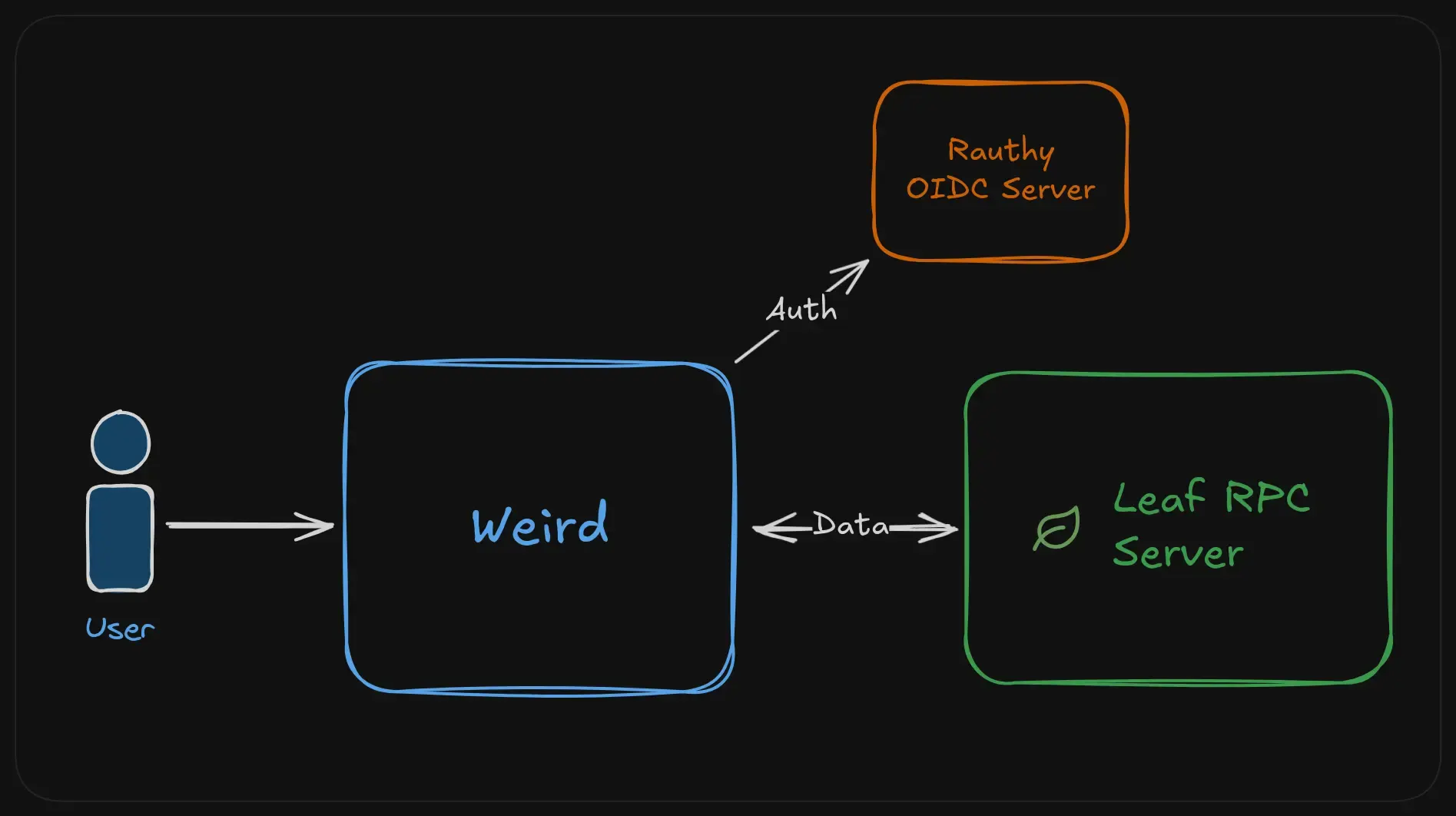
Authentication
Weird uses Rauthy as its auth server and OIDC provider, so that people can, for instance, log into a community git server with their Weird account.
As it stands we only create one Leaf keypair for the server identity. The server is the owner of all of the user profile data. Eventually, though, users will be able to give the Weird server a capability that they’ve issued with their own identity, allowing them to keep control over their identity, or even delegate it to another server, while still being able to use the Weird service to store, edit, and serve their data.
Interoperability
Because of the Entity-Component data model, it is possible for other Weird instances to federate with the main Weird.one instance, while also storing new, custom data.
For example, somebody could make an alternate Weird instance that is customized as a freelancing
site. This would mean creating new components that would be used to store data related to available
gigs, etc. The cool part, though, is that your profile on the freelancing site would still be
compatible with Weird.one because the standardized components such as Name, Description,
Username, etc. are still shared between them.
This can extend to totally different kinds of applications, too, such as personal or communal note taking apps, recipe sharing sites, etc.
Work-in-Progress
Weird and Leaf are both still very work-in-progress. Our Leaf implementation doesn’t follow the draft specification perfectly, and the specification itself needs more work as well.
We are also waiting for the Rust Willow implementation we are using, Iroh, to finish getting up-to-date with the Willow spec. Currently we are faking some pieces of Willow on top of Iroh, and the capability system isn’t working yet, so, for now, all data is 100% public.
We also have a lot of things to figure out still, regarding how we are going to organize data on Leaf. It’s a lot different than a traditional database!
Summary
Overall, there is a lot of work still to do, but things are going very well! Migrating Weird to use the Leaf RPC server has drastically simplified our previous design, and is making it much easier to add new kinds of data as the app evolves.
Leaf is a big experiment, but I’m excited to see how it will turn out, and to continue learning how to make federated software that can provide real-world value.